SQLite is an embedded SQL Library. This means that It is a single library that you link against and now your application has access to a full blown SQL server within the process itself. It does not need a separate tool to access the database. The database is a single file stored on Disk. It also comes with a binary that can read and manipulate databases
When to use SQLite
The advise straight from its creator is to use it to replace flat files. This is specially true if you are writing strucutred data that consist of a set of repeated fields. Usually these can be written in any of the human readable formats - XML, JSON, YAML or good old CSV. So what are the advantages of using a sqlite database instead of one of the above?
The file operations handling is already done for you. Creation, appending, traversing etc are all taken care of. You are just operating on the level of records.
The record structure is enforced for you
The database can be exported anywhere and worked with on any platform
Querying becomes as easy as a SQL query. Any developer worth the title should be able to get at the database and do an initial analysis in just a few minutes. There are excellent Uis to help with this as well
Interop with other tools is very easy. Generating XML, CSV from any table is just one command line away. Sending data to plotting tools is also one command line away.
Tips for writing SQLite files in high throughput applications
-
Always wrap your inserts in transactions. And batch your inserts together. You may have to adjust how many you batch together depending on your RPO requirements. But in general this allows the database to batch things up to save time on individual inserts
-
Use prepared statements. Since you will be inserting the same record structure again and again, there is no point in running your SQL text through the planner again and again. Use a single prepared statement.
-
Dont allocate memory for new records. Use transient variable binding so that we dont allocate and deallocate memory for every single insert statement.
-
Set journal to be in memory. Usually the journal gets written to the disk. If you want to save time on the disk writes you can always force the journal to be in memory
-
Stop the synchronous writes to disk. SQLite will usually fsync after writing to make sure that the data will actually get flushed to the disk controller. We can let the OS determine when it is optimum to flush the data and return without the fsync to save time
-
Page/Cache size. These settings are linked together. Page size determines how much data the process can hold in memory before the OS forces the dirty pages to be flushed to the disk
The Code
The full source code for this example can be found in https://github.com/osadalakmal/sqlite-performance
The main code is as follows
Results
The results can be seen here running on my laptop
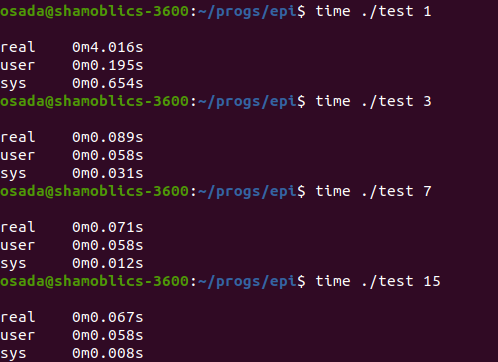
as you can see starting from a baseline of using just prepared queries we keep adding the options mentioned above. By far the biggest impact seems to be from stopping syncrhonous write to disk for db file.
Alternatives to SQLite
There are several reasons that SQLite might not suit your workload.
-
Your data structure might be more suited for KV store. If all you are storing is one opaque value for a given key, a KV store makes definite sense.
-
You might need even more throughput than all the above steps can provide
-
You will need to adjust write amplification/read amplification etc parameters to make sure you fit within the disk budgets.
If this sounds like you, a LSM tree based store will be more suited for you. There are several to choose from. Most of them inspired or forked from the original – LevelDB. Examples are MDB, Tokyo cabinet, RocksDB.
These are based fundamentally on a different set of requirements than SQLite. SQLite was born as a replacement for SQL Clients that needed to retain SQL interface without the servers being present. LSM Tree based KV stores were written to managed very high sustained rates of writes