
Most of us got introduced to containers with docker. In fact it seems that docker for most intents and purposes and has become synonym with containers. However there is a vast landscape of technology underneath this seemingly simple facade of containers. So lets try and dig in to what a container is before we introduce the tooling that we will be using today.
Operating System Level Virtualization
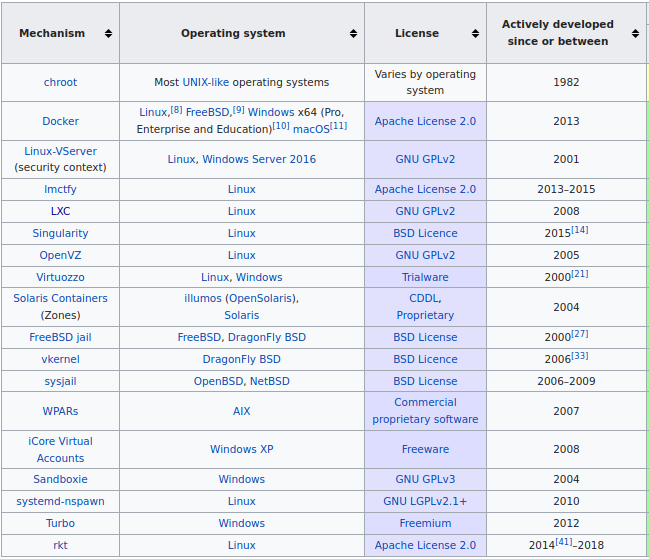
Above is a screenshot of the wikipedia page for OS Level Virtualization Technologies. And notice that there are several technologies now close to 20 years old. So virtualization at OS level is by no means a new concept. Lets take a look at some of them
chroot
This is perhaps the most simple form of a container. It basically changes the root directory to a different directory as specified by the root user. The idea being that the user in the chroot cannot then escape our of that chroot directory in to the real root dir. And for this reason we usually refer to it as a chroot jail.
There are no other privilege checking or access checking enabled. A privilege user can still create special nodes and run commands from with in the chroot. Therefore it is not really suitable as a way to prevent unwanted access from privileged users. Now since the programs usually expect a standard set of directories and files within the root dir, there are tools like jailkit that simplify this procedure
What can this be used for? Well mostly I have seen it being used for testing and builds. Lets look at each use case
For testing, you can think of a chroot as a poor mans container. Once you create a chroot and you have a program that primarily depends on the file system to store data, you can fool it to think it is on a fresh system. And once the program is terminated you can throw away the whole chroot and start again.
For builds, chroots are wonderful because you control every aspect of the whole system from a storage point of view and that is all that is needed for builds. They don’t need remote data storage services for the most part and even if you need to push artifacts to a separate remote storage service that can be achieved by creating a suitable package from the output of the build process itself. Usually you will have a pre-packaged chroot that you store in a tarball containing all the build tools and the fundamental parts of whatever *nix system you are running on. Then after you have done the build you usually package up your build artefacts in to whatever suitable format is (wheels for python, crates for rust, RPM/deb for C etc) and push it to an artefact server. This keeps the builds reproducible as long as the
- chroot tarball is the same
- the source is the same
- the build process is the same
This means that you can reproduce older builds on demand assuming you keep the chroot tarballs around for long enough.
Solaris Zones and Containers
These are probably the best known implementation of OS level virtualization outside of linux. Although FreeBSD jails are quite well known too. I have no experience regarding those though so I will stick with Zones.
A Solaris Container is the combination of system resource controls and the boundary separation provided by zones. Zones are completely separate server instances within a single physical server. In fact these are usually used to provide isolated test servers for the developers since almost no one is going to need a maxed out SPARC-T5-8 to test their application. Sys admins can reduce cost and provide most of the same protections of separate machines on a single machine by using zones.
Systemd nspawn

By now you should not be surprised to learn that there is an implementation of a container technology inside systemd. Everything but the kitchen sink remember?
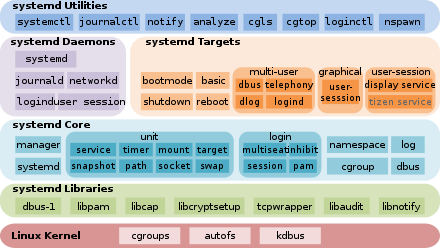
This is implemented on top of cgroups and is supposed to help users with containing processes easily in systemd. It is better in security terms than a chroot since it has process level security features as well. In that way it is similar to lxd or lxd. You can find more information here.
LXC/LXD
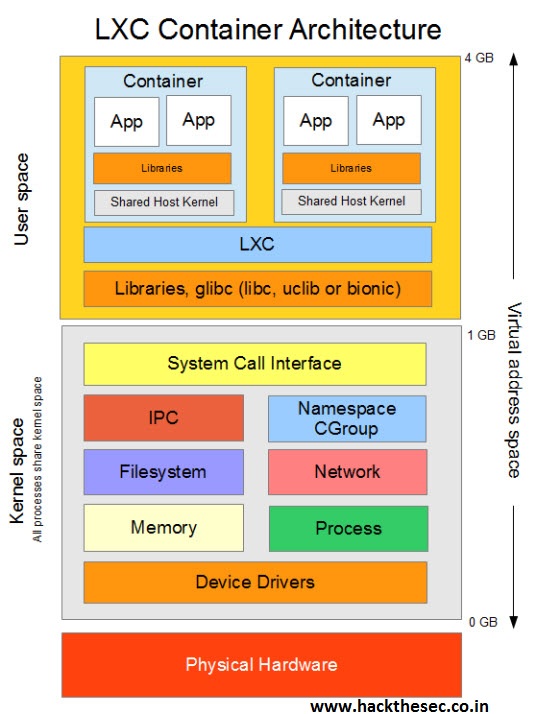
LXC allows running multiple isolated Linux systems (containers) on a control host using a single Linux kernel.
It combines cgroups functionality that allows limitation and prioritization of resources (CPU, memory, block I/O, network, etc.) and namespace isolation functionality that allows complete isolation of an application’s view of the operating environment, including process trees, networking and mounted file systems.
Previously LXC only supported privilege containers though starting with the LXC 1.0 release, it is possible to run containers as regular users on the host using “unprivileged containers”.

LXD is a system container manager. It is basically an alternative implementation of LXC rather than something completely different. Just that it is being pushed by canonical instead of Red Hat (Oops I mean IBM!).
Enter docker
The problem with all these OS level virtualization technology was the audience. In fact it wasn’t even a problem but a feature. They were all aimed at system administrators, developer tooling producers and similar folks who provided services to the developers To be the next big thing apparently you needed to target the developers who needed a dumbed down front end to the whole thing so they could focus on the more interesting things - the business logic.
Docker was created to mostly take existing virtualization technology and simplify it to the point your average developer could operate it without even understanding what was going on under the hood. Like all good tools it allowed people to make use of the technology without worrying too much about how and why of it.
It reduced the setup of the container environment to a simple enough DSL that solved 99% of the problems of the average developer. It reduced the number of concepts the developers had to hold in their heads to a well defined few. And it made the management of the containers and their run time behavior a breeze by introducing a single well defined command line interface.
This meant that for the better part of the last decade docker was known as the defacto container management system and rightly so.
Why not docker?
Even though the user facing parts of the docker eco system was well thought out and intuitive, the backend and the ergonomics were anything but. If you have ever had the (mis?)fortune of having to work with dockerfiles for anything more than simple Hello World projects, you will know how hard it is to produce good ones that make sensible trade offs and produce acceptable image sizes.
-
The builds tend to be too blown up. Image layers are unnecessarily large if you don’t take absolute care. See here for an example.
-
It is very easy to make mistakes. Build time dependent images, have side effects etc. See here for an example
-
The multi stage builds are cumbersome to work with
-
The syntax leaves things to be desired. Mostly you will end up working with shell statements but it is not a shell script. So none of your usual tools will help you (think shellcheck etc)
-
If you don’t have root/Administrator access you cannot use docker. (Not completely correct - see here. But for the most part no one will try this)
These are just a few but you get the idea. And this is where buildah comes in
What buildah is
Buildah take the docker approach of building container images and managing them and first breaks it down in to components. Specifically there are three main components.
- buildah -
This tool allows us to build container images. - podman -
This allows us to manage runtime instances of the containers. - skopeo
This allows us to work with container registries
So it essentialy decomposes the work done by the single docker command. How is this better? Well it allows the unix concept of one tool that does one thing best to work.
Thats it for this post. Next post will discuss OCI vs docker and what different components of a container runtime is and how they come together to run a container.